W niniejszym rozdziale skupiamy się na wykrywaniu i usuwaniu błędów z kodu źródłowego. Jest on rozszerzeniem rozdziału o środowisku wykonawczym i edycyjnym, lecz lektura wymaga znajomości typów danych i instrukcji sterujących. Techniki i umiejętności przedstawione w tym rozdziale są wtórne: nie byłyby potrzebne, gdyby nie ludzka omylność. Dlatego warto je opanować.
Błędy
W idealnym przypadku algorytm zapisany jakimkolwiek sposobem realizuje zamiar jego twórcy. W praktyce nikt nie jest nieomylny, dlatego mamy do czynienia z różnego rodzaju błędami. Oto ich podstawowa klasyfikacja:
- błędy składniowe (syntax errors)
- mają miejsce, kiedy w opisie postępowania zostanie użyta nielegalna konstrukcja, np. wyrażenie arytmetyczne niezgodne z regułami budowy takich wyrażeń, fragment sieci działań zbudowany niezgodnie z regułami jej rysowania, czy też instrukcja języka programowania zapisana niezgodnie z regułami tego języka. Błędy takie uniemożliwiają realizację przetwarzania. Są one dość łatwe do wykrycia.
- błędy logiczne, czyli rzeczowe (logical errors)
- mają miejsce w sytuacji, kiedy schemat postępowania opisany algorytmem nie jest zgodny z jego specyfikacją. Znaczy to, że algorytm prowadzi do innych wyników, niż zamierzono. Błędów tego rodzaju nie da się wykryć automatycznie.
- błędy czasu wykonania (runtime errors)
- mają miejsce, kiedy na skutek nieprzewidzianych okoliczności zajdzie próba wykonania niedozwolonej operacji, np. dzielenia przez zero, obliczenia pierwiastka z liczby ujemnej lub czytania danych z nieistniejącego pliku. Błędy czasu wykonania powstają — jak sama nazwa wskazuje — w toku realizacji przetwarzania, przy czym uniemożliwiają otrzymanie danych wynikowych. Źródłem błędów tego typu mogą być m.in.: błędy logiczne w schemacie przetwarzania, użycie algorytmu w stosunku do danych nie spełniających założeń wstępnych, czy też brak gwarancji zatrzymania algorytmu. Dopracowane algorytmy użytkowe powinny być w miarę możliwości zabezpieczone przed powstawaniem błędów tego typu; w nowo opracowywanych schematach i tworzonym na ich podstawie kodzie są one w praktyce nieuniknione.
Unikanie i eliminacja błędów są poważnymi wyzwaniami związanymi z budową i opisem schematów przetwarzania. Dla ich realizacji podejmuje się działania na różnych poziomach.
Weryfikacja algorytmu polega na zbadaniu, czy robi on to, co robić powinien z punktu widzenia specyfikacji danych, tzn. czy jest skuteczny. Analiza taka wymaga pracy intelektualnej nad schematem działania algorytmu. Jest to zatem czynność, którą musi wykonywać podmiot myślący, a nie automat.
Testowanie polega na badaniu, czy wyniki podawane przez schemat przetwarzania są takie, jak powinny być, tzn. zgodne z deklarowanym celem działania algorytmu. Dlatego należałoby znać wyniki, jakich oczekuje się dla używanych przez siebie zestawów danych testowych.
Użytkowanie algorytmu polega na przygotowywaniu dla niego danych, zlecaniu komuś (np. automatowi) jego wykonania, i odbieraniu wyników, które następnie można wykorzystywać. Najczęściej użytkuje się nie tyle abstrakcyjną postać algorytmu, co opracowany na jego podstawie program. Użytkowanie programu zawierającego błędy logiczne nie ma sensu, gdyż otrzymywane wyniki są bezwartościowe.
W trakcie użytkowania kodu ujawniają się niewykryte do tej pory błędy. Mogą się też pojawić nowe potrzeby ze strony użytkowników. Dla całokształtu działań mających na celu eliminację błędów oraz rozbudowę i wszelkiego rodzaju usprawnienia, używa się terminu konserwacja algorytmu i/lub realizującego go programu.
Wspomaganie zarządzania kodem źródłowym
Wystarczy jedno użycie edytora programisty, by zauważyć, że jest on wyposażony w funkcje ułatwiające tworzenie i kontrolowanie kodu źródłowego. Dlatego właśnie warto z takich narzędzi korzystać. Zakres i sposób realizacji tych ułatwień jest nieco inny w każdym środowisku. Możliwe więc, że używany przez Ciebie edytor zachowuje się nieco inaczej, niż w poniższym opisie.
Najbardziej typowe funkcje edytorów programisty pomocne przy zarządzaniu kodem źródłowym zostały przedstawione w galerii ilustracji.
Ułatwienia wizualnej kontroli poprawności składniowej
Wizualizacja dopasowania nawiasów otwierających i zamykających. Po ustawieniu kursora na nawiasie, odpowiadający mu przeciwległy nawias jest wyróżniany barwą lub krojem pisma.
Wizualizacja elementów składni języka: słów kluczowych, komentarzy, instrukcji, wartości — np. za pomocą barw i kroju pisma.
Rozwijanie i zwijanie elementów blokowych składni (komentarzy, podprogramów, bloków instrukcji podrzędnych). Elementy blokowe mogą być wizualnie ujęte w ramki z przyciskiem umożliwiającym ukrywanie i rozwijanie.
Pomoc podczas tworzenia kodu źródłowego
Automatyzacja wcięć kodu źródłowego podczas pisania instrukcji: bieżąca głębokość wcięcia jest utrzymywana po utworzeniu nowego wiersza; po użyciu klawisza BackSpace, kiedy kursor znajduje się na początku instrukcji, następuje powrót do poprzedniej głębokości wcięć.
Zwiększanie i zmniejszanie głębokości wcięcia zaznaczonego bloku, np. za pomocą klawiszy Tab i Shift Tab.
Podpowiedzi słów w trakcie pisania: rozwijanie listy słów kluczowych, funkcji standardowych, dostępnych zmiennych, metod itp.; klawisz Enter lub Tab powoduje wstawienie słowa z listy do tekstu programu.
Podpowiedzi składni poleceń (funkcji, metod, klas) w trakcie tworzenia kodu; klawisz Enter lub Tab powoduje wstawienie słowa z listy do tekstu programu.
Automatyczne kończenie fraz składniowych języka: w Pythonie rzadko stosowane, bo frazy składniowe tego języka, z wyjątkiem nawiasów i cudzysłowów, nie wymagają zakończenia.
Debuggery i kontrolowane uruchamianie programów
Wykrywanie błędów logicznych i eliminowanie ich z kodu źródłowego jest bardzo istotnym etapem tworzenia programu. W procesie tym pomocne są narzędzia pozwalające symulować wykonywanie programu, przerwać je lub wznowić w dowolnej chwili i szczegółowo badać stan pamięci. Narzędzia takie noszą nazwę debuggerów (odpluskwiaczy).
Do najważniejszych operacji dostępnych za pomocą debuggerów należą:
-
tryb pracy krokowej polegający na wykonywaniu instrukcji
z pliku źródłowego wiersz po wierszu
(
Step over,Step into); - ustawianie pułapek (breakpoints) wymuszających wstrzymanie wykonywania programu przed wskazaną instrukcją. W środowiskach programistycznych pułapka bywa ona często oznaczana czerwoną linią lub czerwonym znaczkiem przy instrukcji;
- wgląd w wartości zmiennych (watch, podgląd, czujki) przechowywanych w pamięci oraz wyrażeń z nich korzystających;
-
możliwość zmiany stanu zmiennej (
Evaluate,Modify) - oraz wiele innych możliwości.
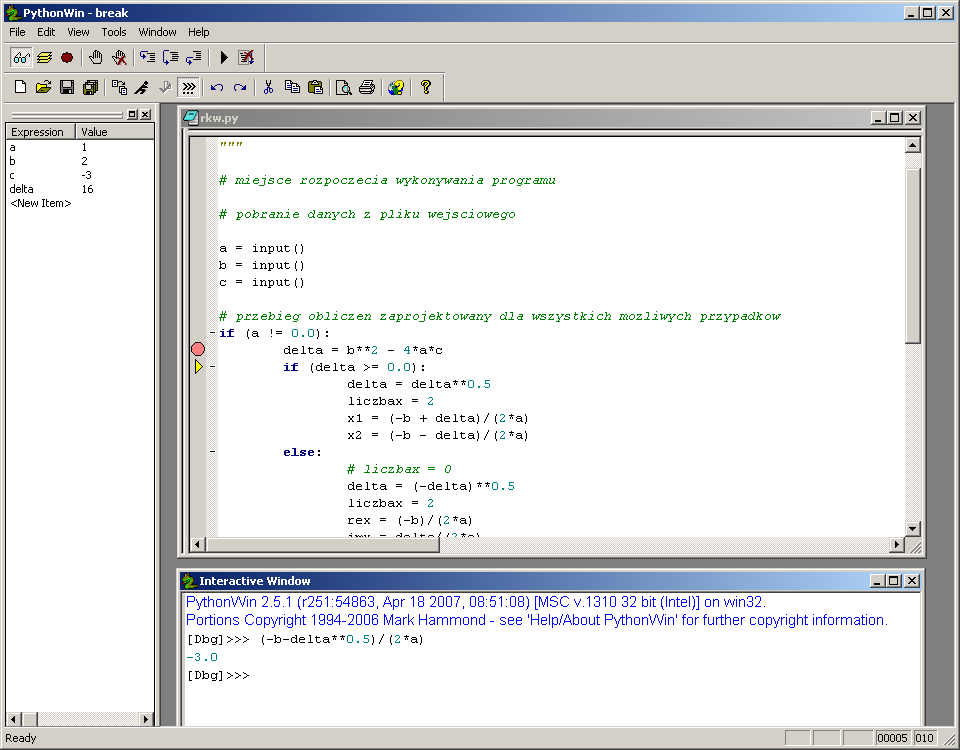
Na ilustracji poniżej przedstawiono sesję debuggera
Pythona w środowisku PythonWin.
Program rkw.py jest w niej wykonywany w trybie krokowym
(File/Run/Step-through in the Debugger, ikonka
biegnącego ludzika na dolnej listwie narzędziowej). Instrukcja z ustawioną
pułapką (File/Debug/Toggle Breakpoint, ikonka dłoni na górnej
listwie narzędziowej) wyróżniona jest czerwonym znakiem. Instrukcja, która zostanie
wykonana w następnej kolejności (File/Debug/Step,
File/Debug/Step over, File/Go,
ikonki ze strzałkami na górnej listwie narzędziowej) wyróżniona jest żółtą strzałką.
W lewym panelu (Watch, ikonka okularów na górnej
listwie narzędziowej) mamy wgląd w stan pamięci programu i w wartości wyrażeń wpisanych
do panelu przez użytkownika. W dolnym panelu interaktywna konsola
(Interactive window, ikonka z symbolem zgłoszenia
interpretera >>> na dolnej listwie narzędziowej) pozwala
na doraźne przeprowadzenie obliczeń pomocniczych, modyfikację stanu zmiennych, itp.
Przy testowaniu programów Pythona można korzystać także z innych debuggerów. Kilka z nich zostało zamieszczonych w spisie oprogramowania. Oferują one równoważne funkcje, jednak mogą się różnić wyglądem okna roboczego i sposobem jego obsługi.
Szerszy wgląd w narzędzia i środowiska programistyczne, pozwalające na tworzenie, uruchamianie i dogłębne testowanie kodu źródłowego oraz na generowanie z niego programów wykonywalnych daje osobna galeria ilustracji.
W kolejnych sekcjach krótko omówimy podstawową metodykę diagnozowania kodu źródłowego. Diagnozowany program musi być poprawny pod względem składniowym; w przeciwnym razie jego uruchomienie nie będzie możliwe.
Sygnalizację błędów składniowych w kodzie źródłowym demonstruje osobna galeria ilustracji.
Praca krokowa
Domyślnie program jest uruchamiany w trybie ciągłym (non stop mode, go, run), tak samo jak bez użycia debuggera.
W trybie pracy krokowej po wykonaniu każdej instrukcji, ew. każdego wiersza kodu źródłowego, praca jest wstrzymywana. Niektóre debuggery mają kilka trybów pracy krokowej. Różnią się one traktowaniem podprogramów: albo wywołują je w jednym kroku (step over), albo instrukcja po instrukcji (step into).
W nowoczesnych debuggerach wysokiej klasy oferowana jest nawet funkcja kroku wstecz, czyli anulowania skutków ostatnio wykonanej instrukcji (o ile w odniesieniu do pamięci programu jest to możliwe, nie sposób wyobrazić sobie cofnięcia wykonanej operacji systemowej, takiej jak nadpisanie pliku lub przesłanie wydruku do urządzenia).
Przejście z trybu krokowego do trybu ciągłego jest możliwe w dowolnym momencie (go, continue).
Niektóre debuggery mają też funkcję wymuszającą natychmiastowe przejście z trybu ciągłego w tryb krokowy (break). Przy tej metodzie nie sposób przewidzieć, przy której instrukcji program zostanie wstrzymany; zależy to m.in. od chwili, w której zażądano przerwania pracy.
Pułapki
Pułapki (breakpoints) są miejscami w kodzie źródłowym, po dojściu do których wykonywanie programu w trybie ciągłym ma zostać wstrzymane.
Na ogół pułapki są ustawiane za pomocą funkcji menu lub skrótów klawiatury, a ich lokalizacja jest czytelnie oznaczona (np. na marginesie edytora lub przez wyróżnienie wiersza kodu).
Inny wariant ustawiania pułapek wykorzystuje położenie kursora w edytorze kodu źródłowego w chwili uruchomienia programu (go to cursor).
Podgląd
Podgląd zawartości zmiennych i wyrażeń (Watch, ‘czujki’) pozwala wizualnie badać stan pamięci i konfrontować go z zamiarami autora programu. Jest to narzędzie pomocne przy wykrywaniu uporczywych błędów, a także nieocenione w procesie nauki programowania.
Konsola / modyfikacje stanu
W większości debuggerów Pythona konsola interaktywna jest do dyspozycji operatora. Da się z niej korzystać w trybie krokowym lub po przerwaniu trybu ciągłego.
Pierwszy sposób jej wykorzystania wiąże się z kontrolą wartości wyrażeń. Jest to funkcja zbliżona do tej oferowanej przez podgląd pamięci programu.
Druga możliwość użycia konsoli interpretera wiąże się z modyfikacją obiektów programu.
Obsługa wyjątków z poziomu programu, czyli czy zabawki naprawiają się same
Dotychczas traktowaliśmy błędy jako uciążliwą przypadłość, będącą czy to efektem pomyłek, czy błędnie przygotowanych danych. W praktyce nie da się ani przewidzieć wszystkich przypadków użycia programu, ani wynikających z tego błędów i ich konsekwencji. Błędy są codziennością i trzeba sobie z nimi radzić.
W nowoczesnych językach programowania, w tym w Pythonie, istnieją mechanizmy umożliwiające wykrycie próby niedozwolonej operacji i zapobieżenie jej wykonaniu. Noszą one ogólną nazwę mechanizmów obsługi wyjątków. Nie będziemy wgłębiać się w szczegóły techniczne ich stosowania — wymaga to znacznie szerszych ram czasowych — jednak porównanie dwóch podejść do konkretnego zagadnienia pokaże, w jaki sposób obsługa wyjątków ułatwia tworzenie czytelnego i niezawodnego kodu.
Przyjmijmy, że program ma pobrać od użytkownika nazwę pliku, następnie otworzyć ten plik, odczytać z jego zawartości kolumnę liczb, po czym obliczyć logarytmy tych liczb. Możliwe są następujące sytuacje:
- użytkownik nie podał nazwy pliku (np. chcąc zrezygnować z jego czytania)
- podany przez użytkownika tekst nie może być nazwą pliku (np.
'::\\\\:?:') - plik o wskazanej nazwie nie istnieje
- plik o wskazanej nazwie nie da się odczytać
- zawartość pliku jest inna niż oczekiwano (np. nie zawiera kolumny liczb)
- nie da się obliczyć logarytmu (np. bo któraś z liczb nie jest dodatnia)
W tradycyjnym ujęciu prosty ciąg czynności
nazwa = podaj nazwę pliku otwórz plik nazwa x = lista liczb odczytanych z pliku zamknij plik y = lista logarytmów liczb z x
uzupełniony o zabezpieczenia na wypadek przewidzianych błędów, mógłby wyglądać następująco:
nazwa = podaj nazwę pliku
if (podano nazwę):
otwórz plik nazwa
if (plik jest otwarty):
czytaj zawartość pliku
if (zawartość składa się z liczb):
utwórz listę liczb x
if (wszystkie liczby są dodatnie):
utwórz listę logarytmów liczb y
zamknij plik
(zauważmy zaburzenie kolejności instrukcji w porównaniu z pierwotnym projektem). Komplikacje narastają w miarę przewidywania coraz to nowych możliwości błędów.
W przypadku zastosowania metod obsługi wyjątków kod znacznie się upraszcza, a co najważniejsze — jego zasadnicza część, wyróżniona kolorem, jest taka sama lub prawie taka sama, jak w pierwotnym projekcie:
try: # wykonuj
nazwa = podaj nazwę pliku
otwórz plik nazwa
x = lista liczb odczytanych z pliku
zamknij plik
y = lista logarytmów liczb z x
except: # zaś w sytuacjach nadzwyczajnych:
jeśli nie podano nazwy:
wykonaj czynności przewidziane w przypadku tego typu błędu
jeśli plik nie istnieje:
wykonaj czynności przewidziane w przypadku tego typu błędu
jeśli dana nie jest liczbą:
wykonaj czynności przewidziane w przypadku tego typu błędu
jeśli argument logarytmu nie jest liczbą dodatnią:
wykonaj czynności przewidziane w przypadku tego typu błędu
przy każdym innym rodzaju wyjątku:
przekaż komunikat o nieprzewidzianym błędzie
Fragment oznaczony kolorem zielonym będzie wykonywany zgodnie z następstwem instrukcji. Każda sytuacja nadzwyczajna, która domyślnie spowodowałaby przerwanie działania programu, w tym przypadku jedynie przerwie ciągłość wykonywania tego podstawowego bloku, i spowoduje przeskok do obsługi danego typu wyjątku.
Z obsługą wyjątków w Pythonie
związane jest użycie słów kluczowych:
try dla oznaczenia podstawowego toku wykonywanej czynności,
except dla oznaczenia instrukcji postępowania dla poszczególnych rodzajów błędów,
finally dla oznaczenia końcowych czynności, wykonywanych po (pomyślnym lub nie) przejściu przez cały blok try,
oraz raise dla sprowokowania wystąpienia danego typu wyjątku w określonej sytuacji.
Przy tym instrukcja postępowania, z czysto proceduralnej (co i w jakiej kolejności robić) przeradza się częściowo w deklaratywną (co byśmy chcieli, żeby było zrobione).
Kod z obsługą wyjątków można np. umieścić wewnątrz pętli, której zakończenie jest możliwe jedynie w przypadku pomyślnego przejścia przez wszystkie wymagane instrukcje. Na przykład
zrobione = False
while not zrobione:
try:
to, co trzeba zrobić
...
zrobione = True
except typ błędu:
postępowanie na wypadek tego rodzaju błędu
...
Przykład powyższy jest zaledwie szkicem w pseudojęzyku. Zagadnienia obsługi wyjątków wykraczają poza zamierzony zakres tego opracowania.
Co i w jakiej kolejności sprawdzać
Dobrym nawykiem jest narzucenie takiego stylu pracy, w którym dbałość o poprawność logiczną jest stałym elementem. Pełne omówienie tego tematu nie jest możliwe w krótkich ramach tego kursu. Ale kilka podstawowych reguł warto znać:
- Pamiętaj, że kod źródłowy jest odzwierciedleniem algorytmu, a ten z kolei — sposobem na niezawodne uzyskanie danych wynikowych. Zatem zanim zaczniesz cokolwiek pisać, musisz znać swój cel. Dotyczy to nie tylko całości pracy, ale każdego jej etapu.
- Twórz schematy blokowe i opisy nieformalne, zanim rozpoczniesz pisanie kodu.
- Dziel dużą pracę na etapy. Używaj podprogramów do ich realizacji.
- Testuj podprogramy na możliwie różnorodnych zestawach danych, nawet nie związanych bezpośrednio z Twoim problemem.
- Dbaj o poprawność logiczną i składniową na każdym etapie pracy:
- w skali mikro znaczy to: opracuj działający schemat dla szczególnego przypadku i uogólniaj go zgodnie z logiką (metoda wstępująca);
- w skali makro znaczy to: stwórz makietę, która chociaż „nic nie robi”, to zawiera gotowy schemat logiczny całości nadający się do testowania; następnie stopniowo wypełniaj ją szczegółami (metoda zstępująca);
- nie przepisuj programu jak tekstu, od początku do końca. Przyjmij taką kolejność, żeby w każdym momencie program — mimo że nieukończony — był poprawny składniowo i dzięki temu dawał się uruchomić.
- Ukrywaj szczegóły w podprogramach. Nadawaj obiektom nazwy związane z ich przeznaczeniem. Staraj się, by lektura kodu pozwalała na zrozumienie, jaki jest cel Twojej pracy.
- Wykorzystuj posiadane podprogramy wszędzie, gdzie to możliwe.
- Pisz komentarze. Kiedy wrócisz do tego samego miejsca za parę tygodni, okażą się nieocenione.
- Na czas układania kodu twórz wydruki kontrolne za pomocą funkcji
printi używaj debuggerów do sprawdzania pośrednich etapów obliczeń. Konfrontuj je z wynikami, jakie uważasz za poprawne. - Od czasu do czasu, tam gdzie to możliwe, postaw się w roli procesora i samodzielnie przeprowadź obliczenia dokładnie według napisanych w kodzie instrukcji.
Pytania kontrolne
- Jakie oprogramowanie może służyć do tworzenia programu źródłowego w Pythonie?
- Wymień najważniejsze przyczyny i rodzaje błędów w algorytmach i kodzie
- Wymień sposoby wykrywania różnego rodzaju błędów
- Jakie oprogramowanie może służyć do kontrolowanego przebiegu napisanego przez Ciebie programu?
- Do czego służy krokowy tryb pracy debuggera?
- Do czego służą czujki?
- Do czego służą pułapki?


